DensePose:
Dense Human Pose Estimation In The Wild
Announcements:
- DensePose task is a part of COCO and Mapillary Joint Recognition Challenge Workshop at ICCV 2019.
See the challenge description and description of the new evaluation metric and the evaluation server.
Dense human pose estimation aims at mapping all human pixels of an RGB image to the 3D surface of the human body.


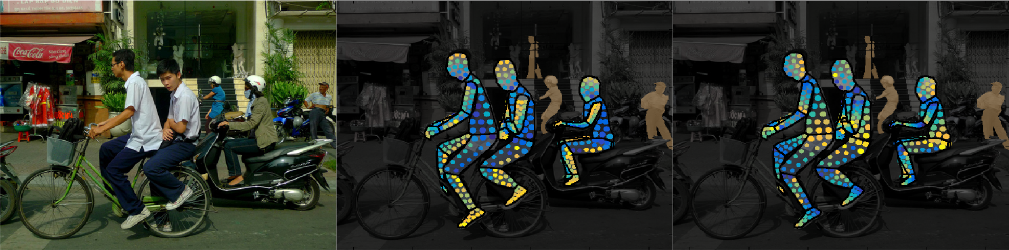


We also provide notebooks to visualize the collected annotations on the images and on the 3D model.
A notebook to visualize the annotations is provided at the repostitory.






- We introduce DensePose-COCO, a large-scale ground-truth dataset with image-to-surface correspondences manually annotated on 50K COCO images.
- We propose DensePose-RCNN, a variant of Mask-RCNN, to densely regress part-specific UV coordinates within every human region at multiple frames per second.
DensePose-COCO Dataset
We involve human annotators to establish dense correspondences from 2D images to surface-based representations of the human body. If done naively, this would require by manipulating a surface through rotations - which can be frustratingly inefficient.
Instead, we construct a two-stage annotation pipeline to efficiently gather annotations for image-to-surface correspondence.
As shown below, in the first stage we ask annotators to delineate regions corresponding to visible, semantically defined body parts. We instruct the annotators to estimate the body part behind the clothes, so that for instance wearing a large skirt would not complicate the subsequent annotation of correspondences.
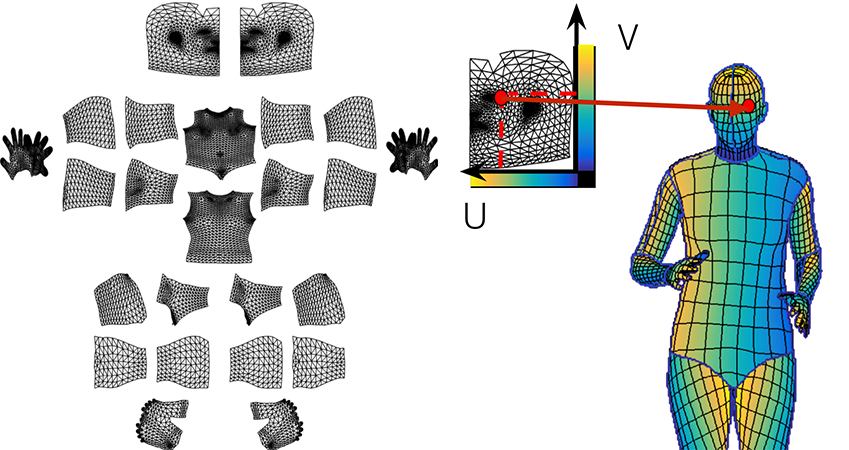
In the second stage we sample every part region with a set of roughly equidistant points and request the annotators to bring these points in correspondence with the surface. In order to simplify this task we `unfold' the part surface by providing six pre-rendered views of the same body part and allow the user to place landmarks on any of them. This allows the annotator to choose the most convenient point of view by selecting one among six options instead of manually rotating the surface.
We use the SMPL model and SURREAL textures in the data gathering procedure.
As shown below, in the first stage we ask annotators to delineate regions corresponding to visible, semantically defined body parts. We instruct the annotators to estimate the body part behind the clothes, so that for instance wearing a large skirt would not complicate the subsequent annotation of correspondences.
In the second stage we sample every part region with a set of roughly equidistant points and request the annotators to bring these points in correspondence with the surface. In order to simplify this task we `unfold' the part surface by providing six pre-rendered views of the same body part and allow the user to place landmarks on any of them. This allows the annotator to choose the most convenient point of view by selecting one among six options instead of manually rotating the surface.
We use the SMPL model and SURREAL textures in the data gathering procedure.
The two-stage annotation process has allowed us to very efficiently gather highly accurate correspondences. We have seen that the part segmentation and correspondence annotation tasks take ap- proximately the same time, which is surprising given the more challenging nature of the latter task.
We have gathered annotations for 50K humans, collecting more then 5 million manually annotated correspondences. Below are visualizations of annotations on images from our validation set: Image (left), U (middle) and V (right) values for the collected points.
Download
Please note that the DensePose-COCO and DensePose-PoseTrack datasets are distributed under NonCommercial Creative Commons license.DensePose-COCO
The download links are provided in the installation instructions of the DensePose repository.We also provide notebooks to visualize the collected annotations on the images and on the 3D model.
DensePose-PoseTrack
The download links are provided in the DensePose-Posetrack instructions of the repository.A notebook to visualize the annotations is provided at the repostitory.
DensePose-RCNN System
Similar to DenseReg, our strategy to find dense correspondence by partitioning the surface. And for every pixel, determine:
- which surface part it belons to,
- where on the 2D paremeterization of the part it corresponds to.
We adopt the architecture of Mask-RCNN with the Feature Pyramid Network (FPN) features, and ROI-Align pooling so as to obtain dense part labels and coordinates within each of the selected regions.
As shown below, we introduce a fully-convolutional network on top of the ROI-pooling that is entirely devoted to two tasks:
As shown below, we introduce a fully-convolutional network on top of the ROI-pooling that is entirely devoted to two tasks:
- Generating per-pixel classification results for selection of surface part.
- For each part regressing local coordinates within part.
The DensePose-RCNN system can be trained directly using the annotated points as supervision. However, we obtain substantially better results by ``inpainting'' the values of the supervision signal on positions that are not originally annotated. To achieve this, we adopt a learning-based approach where we firstly train a ``teacher'' network: A fully-convolutional neural network(depicted below) that reconstructs the ground-truth values given images scale-normalized images and the segmentation masks.
We further improve the performance of our system using cascading strategies. Via cascadning, we exploit information from related tasks, such as keypoint estimation and instance segmentation, which have successfully been addressed by the Mask-RCNN architecture. This allows us to exploit task synergies and the complementary merits of different sources of supervision.
Team
Rıza Alp Güler
Imperial College London
Natalia Neverova
Facebook AI Research
Vasil Khalidov
Facebook AI Research
Iasonas Kokkinos
University College London
Cite
@inproceedings{guler2018densepose,
title={Densepose: Dense human pose estimation in the wild},
author={ G{\"u}ler, R{\i}za Alp and Neverova, Natalia and Kokkinos, Iasonas},
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
pages={7297--7306},
year={2018}
}